같은 회사 안에서 '재구매율'이 다섯 개로 갈리는 이유. AI 분석이 틀리는 진짜 원인은 모델이 아니라 의미의 모호함이며, 시맨틱 레이어로 정의를 통일하면 정확도가 올라갑니다.

📚 시리즈 | 프롬프트 뒤에 숨은 것을 보는 눈 (2/3) AI에게 "분석해줘" 한 줄을 던지는 시대, 그 답 뒤에 무엇이 숨어 있는지 볼 줄 아는 '눈'을 3편에 걸쳐 키웁니다. ① 의심하는 눈 → ② 말의 모호함을 꿰뚫는 눈 → ③ 토대를 보는 눈 순서로 이어지며, 지금 보시는 글은 그 두 번째인 '두 번째 눈' 편입니다.
같은 회사, 같은 단어, 다른 숫자
한 이커머스 회사의 주간 회의. 누군가 묻습니다. "우리 재구매율 지금 몇이에요?"
마케팅팀: "32%요. 캠페인 받은 고객이 다시 산 비율이요."
CS팀: "음, 저희는 45%로 보고 있어요. 한 번이라도 두 번째 주문을 한 고객 기준요."
재무팀: "21%인데요. 같은 분기 안에 다시 결제한 사람만 셉니다."
세 팀 다 거짓말을 하지 않았습니다. 모두 성실하게 계산했습니다. 그런데 답이 세 개입니다. 여기에 데이터 분석가가 쓰는 기준, 대표님이 머릿속에 가진 기준까지 더하면 한 회사 안에 '재구매율'이 다섯 개쯤 떠다닙니다.
지난 편에서 AI가 "재구매율 23%"라고 자신만만하게 답하고 빈칸을 혼자 채웠다고 했습니다. 이번 편의 핵심은 이것입니다. AI가 빈칸을 멋대로 채우는 건 모델이 멍청해서가 아니라, 애초에 우리 회사 안에 정답이 흩어져 있기 때문입니다.
AI가 빠지는 3가지 함정
AI에게 우리 회사 데이터를 그냥 던져주면, 사람도 헷갈려 하는 바로 그 지점에서 똑같이 헷갈립니다. 이커머스에서 가장 자주 나오는 세 가지를 봅니다.
함정 1. 같은 단어, 다른 정의
'매출' 한 단어를 봅시다.
주문이 들어온 날 기준인가요, 결제가 완료된 날 기준인가요?
취소와 환불은 빼나요?
배송비와 쿠폰 할인은 포함하나요?
어느 쪽을 고르느냐에 따라 같은 달 매출이 수천만 원씩 차이 납니다. 사람은 맥락을 보고 적당히 맞추지만, AI는 그 맥락을 모릅니다. 정의가 정해져 있지 않으면 AI는 그저 손에 잡히는 숫자를 더할 뿐입니다.
함정 2. 한 명을 여러 명으로 세는 실수
이건 좀 더 미묘합니다. 장바구니로 비유해 보겠습니다.
한 고객이 한 번의 주문에서 상품 3개를 샀다고 합시다. 데이터에서 '고객'과 '주문'과 '상품'을 잘못 연결하면, 이 한 명이 세 명처럼 계산됩니다. 상품 한 줄마다 고객이 한 번씩 세지기 때문입니다.
그 결과 고객 수가 부풀려지고, 1인당 매출은 줄어들고, 재구매율은 엉뚱해집니다. 화면에 나오는 표는 멀쩡해 보이지만, 숫자의 뿌리가 어긋나 있습니다. 사람도 실수하는 이 연결을, AI도 똑같이 틀립니다.
함정 3. "지난달"이라는 모호한 시간
"지난달 성과 보여줘"라는 말도 함정입니다. '지난달'이 달력상 한 달(지난 1일부터 말일까지)인지, 오늘 기준 최근 30일인지에 따라 포함되는 주문이 달라집니다. 월말 프로모션이 걸쳐 있으면 차이는 더 커집니다.
진짜 반전: 모델을 바꿔도 소용없었다
여기서 많은 분이 기대하는 해법은 "그럼 더 똑똑한 AI를 쓰면 되겠네"입니다. 그런데 실제 데이터는 정반대를 가리킵니다.
AI 분석을 깊게 파고든 Anthropic은, 같은 질문에 대한 분석 정확도를 약 21%에서 95% 이상으로 끌어올렸습니다(확인된 출처: Anthropic 공식 블로그). 비결은 더 비싼 모델이 아니었습니다. '의미'를 정리한 것이었습니다. 무엇이 '활성 고객'인지, 무엇이 '매출'인지를 회사 차원에서 한 번 못 박아두고, AI가 그 정의를 쓰게 한 것입니다.
더 결정적인 실험도 있습니다. 분석 도구 회사 Cube가 진행한 벤치마크(2026)에서, 서로 다른 AI 모델 세 개(Claude Opus 4.7, Claude Sonnet 4.6, GPT-5.4)에 같은 정리 작업을 적용했습니다. 여기서 '정리 작업'이란 거창한 게 아니라, 데이터의 의미와 규칙을 적은 4KB짜리 정의 문서 한 장을 함께 건넨 것이었습니다. 그 결과 세 모델 모두 정확도가 17~23%포인트씩 올랐고, 모델 사이의 차이는 거의 사라졌습니다(적용 전 45.5~50.5% → 적용 후 67.7~68.7%로 통계적으로 구분 불가). 확인된 출처: Cube 블로그, Why semantic layers make LLM analytics reliable (논문판: arXiv:2604.25149).
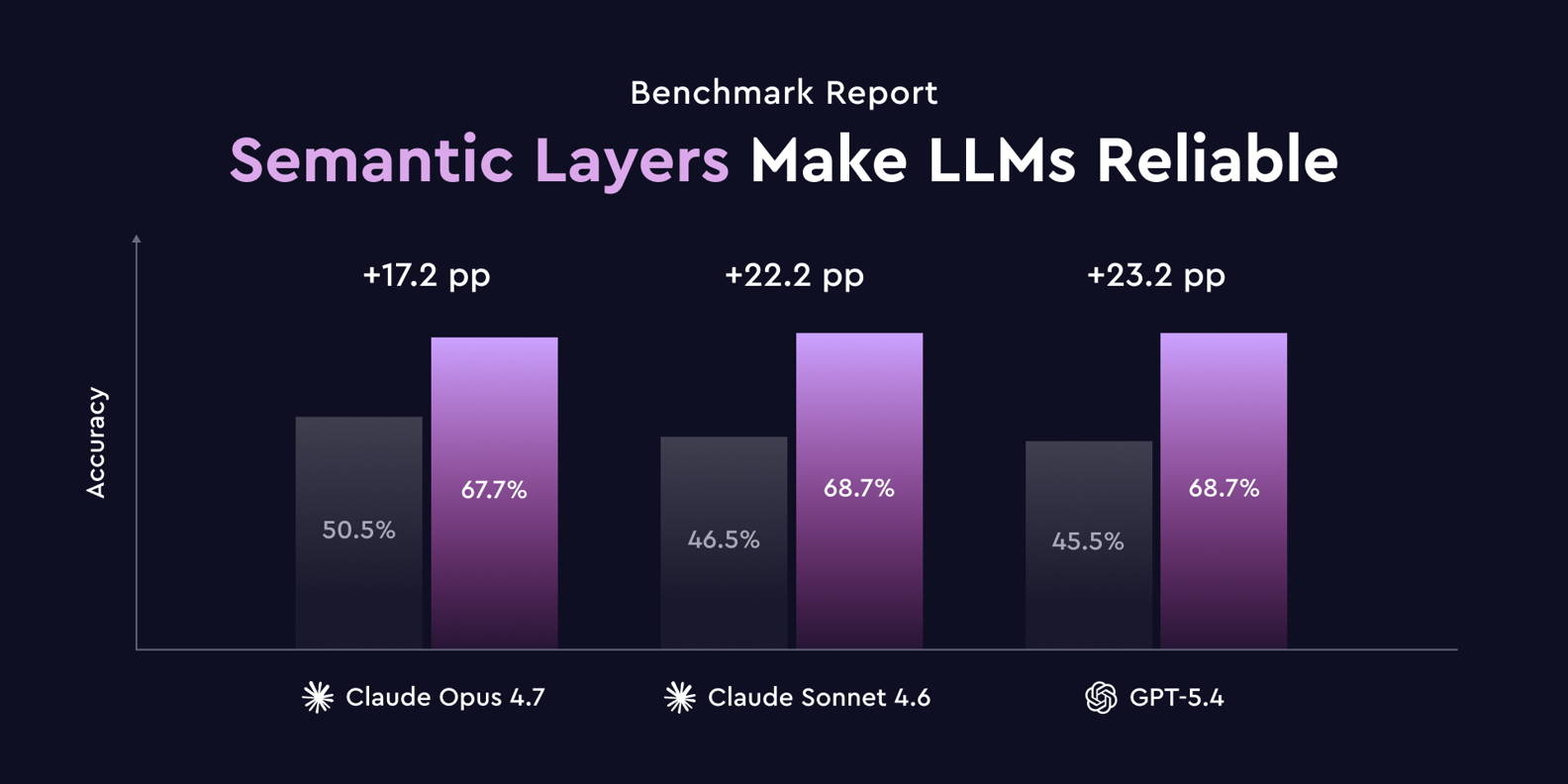
이미지 출처: Cube, Why semantic layers make LLM analytics reliable
이 결과가 말하는 바는 분명합니다.
AI 분석의 정확도 상한선은 모델이 아니라, 우리가 데이터에 부여한 의미가 결정합니다.
두 번째 눈: 말의 모호함을 꿰뚫는 눈
첫 번째 눈이 "이 답을 의심하라"였다면, 두 번째 눈은 "우리가 쓰는 말부터 모호하지 않은가"를 보는 눈입니다.
AI가 틀린 답을 줬을 때, 화를 내야 할 대상은 AI가 아닙니다. 우리 회사 안에서 '재구매율'이 다섯 개로 굴러다니도록 방치한 우리 자신입니다. 새 AI를 기다리는 것보다, 오늘 '재구매율은 이렇게 센다'를 한 줄로 정하는 것이 정확도에 훨씬 큰 영향을 줍니다.
AI를 바꾸지 말고, 말을 정리하세요.
그렇다면 '말을 정리한다'는 건 구체적으로 무엇을 갖추는 걸까요? 마지막 편에서는 대표와 마케터가 각자 무엇을 준비해야 하는지, 보이지 않던 토대를 행동 목록으로 정리합니다.
한 걸음 더: '시맨틱 레이어'란 무엇인가
방금 본 '의미를 정리한 4KB짜리 문서', 이것을 체계화한 것이 바로 시맨틱 레이어 (Semantic Layer, 의미 계층) 입니다. 전문 용어처럼 들리지만 역할은 단순합니다. 비즈니스 언어와 데이터베이스 사이의 번역기입니다. '재구매율'이라는 사람의 말을, 어떤 테이블을 어떻게 계산해야 하는지로 옮겨주는 사전 겸 자동 변환기죠.
무엇으로 이루어지나
시맨틱 레이어는 보통 다음 요소로 구성됩니다.
개체(Entity): 고객, 주문, 상품처럼 분석의 기준이 되는 대상
차원(Dimension): 기간, 채널, 지역, 세그먼트 등 데이터를 쪼개 보는 기준
사실값(Measure): 주문 금액, 클릭 수처럼 한 줄 한 줄의 원시 숫자
지표(Metric): GMV, 재구매율, ROAS처럼 사실값을 모아 만든 회사 공식 정의
관계(Relationship): 개체들을 잇는 검증된 연결 경로 (2편의 '한 명을 세 명으로 세는 실수'를 원천 차단하는 부분)
왜 이게 정확도를 끌어올리나
핵심은 AI에게 'SQL을 짜라'가 아니라 '무엇을 볼지만 고르라'고 시키는 것입니다.
사용자 질문 → AI는 '어떤 지표를, 어떤 차원으로' 볼지만 선택 → 컴파일러가 '어떻게' 계산할지(조인, 집계)를 정해진 규칙대로 처리 → 검증된 결과
AI가 조인이나 합산 방식을 발명할 여지 자체가 없어집니다. 그래서 '잘못된 합산'이나 '엉뚱한 조인' 같은 실패가 구조적으로 막힙니다. 덤으로 개인정보(PII) 접근 권한 같은 규칙도 이 계층에 한 번 걸어두면 모든 질문에 자동으로 적용됩니다.
어떻게 시작하나
거창한 새 시스템을 사는 일이 아닙니다. 가장 많이 쓰는 핵심 지표 몇 개의 정의를 코드 한 곳에 못 박는 것부터 시작합니다. 기술적으로는 dbt 같은 도구로 정의를 작성하고, 데이터 창고(예: Snowflake)의 표준 객체로 배포해 기존 PR 검수 흐름 안에서 관리하는 방식이 흔히 쓰입니다. 중요한 건 도구가 아니라 "이 지표는 이렇게 센다"를 한 곳에서 관리하고, 사람도 AI도 그것만 보게 만드는 원칙입니다.
자주 묻는 질문
Q. 정의를 통일하는 게 그렇게 중요한가요? A. 정확도의 상한선을 결정하는 요소입니다. 정의가 흩어져 있으면 아무리 좋은 AI도 그 위에서 헤맵니다. 모델 세 개를 바꿔도 차이가 사라졌다는 실험이 이를 보여줍니다(Cube 벤치마크, 2026).
Q. 작은 회사도 해당되나요? A. 오히려 더 해당됩니다. 팀이 작을수록 정의를 문서로 남기지 않고 머릿속에만 두는 경우가 많아, 사람이 바뀌면 숫자의 의미도 같이 사라집니다.
다음 편: 「똑똑해져야 하는 건 AI가 아니라 우리 데이터」 — 무엇을 갖춰야 하는가
You may also interested in





Join our newsletter for the latest insights and updates