AI 분석의 정확도를 결정하는 건 모델이 아니라 데이터의 토대입니다. 정규 데이터, 진실의 원천, 스킬, 검증으로 이루어진 토대를 무엇부터 갖춰야 하는지 대표와 마케터용 체크리스트로 정리합니다.

📚 시리즈 | 프롬프트 뒤에 숨은 것을 보는 눈 (3/3) AI에게 "분석해줘" 한 줄을 던지는 시대, 그 답 뒤에 무엇이 숨어 있는지 볼 줄 아는 '눈'을 3편에 걸쳐 키웁니다. ① 의심하는 눈 → ② 말의 모호함을 꿰뚫는 눈 → ③ 토대를 보는 눈 순서로 이어지며, 지금 보시는 글은 시리즈를 매듭짓는 마지막 '세 번째 눈' 편입니다.
지금까지의 두 개의 눈
1편에서 우리는 의심하는 눈을 얻었습니다. AI가 준 깔끔한 숫자 뒤에는 누군가 혼자 채운 빈칸이 숨어 있다는 것.
2편에서는 말의 모호함을 꿰뚫는 눈을 얻었습니다. AI가 틀리는 진짜 이유는 모델이 아니라, 우리 회사 안에 '재구매율'이 다섯 개로 흩어져 있기 때문이라는 것. 그리고 정확도의 상한선은 모델이 아니라 우리가 데이터에 부여한 의미가 결정한다는 것.
이제 마지막 질문이 남았습니다. "그래서, 무엇을 갖춰야 하는가?"
보이지 않던 토대, 4가지
AI 분석을 21%에서 95%까지 끌어올린 회사들이 실제로 갖춘 것은 화려한 기술이 아니라 네 가지 평범한 토대였습니다(확인된 출처: Anthropic 공식 블로그). 전문 용어를 걷어내고 옮기면 이렇습니다.
① 정답이 하나인 데이터
같은 질문에는 같은 숫자가 나와야 합니다. 그러려면 팀마다 따로 굴리는 엑셀과 대시보드가 아니라, 회사가 공식으로 인정하는 숫자 한 벌이 있어야 합니다. "우리 회사 매출은 여기서 본다"가 정해져 있는 상태입니다.
② 용어 사전 (= 시맨틱 레이어)
가장 핵심입니다. '재구매율은 이렇게 센다', '신규 고객은 첫 구매 기준이다', '매출은 환불을 뺀 결제액이다' — 이런 정의를 한 곳에 못 박아두고, 사람도 AI도 모두 그것을 쓰게 하는 것입니다. 전문가들은 이걸 '시맨틱 레이어(의미 계층)'라 부르지만, 쉽게 말하면 회사 공용 용어 사전입니다. 이게 있으면 AI는 더 이상 빈칸을 멋대로 채우지 않습니다. 사전을 펴 보면 되니까요.
③ 절차의 표준화
"이런 질문이 들어오면, 어떤 데이터를 어떤 순서로 본다"를 정해두는 것입니다. 숙련된 분석가의 머릿속 절차를 글로 남겨두면, AI도 그 길을 따라가 같은 품질의 답을 냅니다.
④ 검증하는 습관
AI의 답을 그대로 받지 않고 한 번 더 의심하는 절차입니다. 1편의 '의심하는 눈'을 조직 차원의 습관으로 만든 것이죠. 실제로 답을 비판적으로 한 번 더 검토하게 했더니 정확도가 약 6%포인트 더 올랐습니다(확인된 출처: Anthropic 공식 블로그).
오늘 바로 해볼 체크리스트
대표님을 위한 체크리스트
우리 회사의 핵심 지표(매출, 재구매율, 신규 고객) 정의가 문서로 존재하나요?
같은 질문을 두 팀에 물으면 같은 숫자가 나오나요?
AI가 준 숫자를 검토 없이 의사결정에 쓰고 있지는 않나요?
마케터를 위한 체크리스트
AI에게 분석을 시킬 때 정의를 함께 적나요? ("신규=첫 구매, 기간=최근 30일, 환불 제외")
받은 숫자를 보고서에 넣기 전에 "이 정의가 맞나" 한 번 확인하나요?
자주 쓰는 지표의 정의를 팀과 공유된 문서로 갖고 있나요?
진짜 출발점: 흩어진 고객 데이터를 하나의 의미로
네 가지 토대 중에서도 이커머스에 가장 먼저 필요한 건 고객 데이터를 하나의 의미로 모으는 것입니다. 주문, 결제, 행동, 채널이 제각각 흩어져 있으면 '재구매율' 같은 단어는 영원히 다섯 개로 남습니다.
데이터라이즈는 바로 이 출발점을 돕습니다. 흩어진 고객 데이터를 한곳에 모아 통일된 의미를 부여하고, 누가 묻든 같은 정의로 같은 답이 나오는 토대를 만듭니다. AI에게 "우리 VIP 고객 행동 분석해줘"라고 물었을 때, AI가 빈칸을 멋대로 채우는 대신 우리 회사가 정한 'VIP'의 정의를 그대로 따르게 되는 것. 그것이 셀프서비스 분석이 실제로 작동하기 시작하는 순간입니다.
세 번째 눈: 토대를 보는 눈
세 번째 눈은 답이 아니라 토대를 보는 눈입니다. 더 나은 답을 찾기 전에, 그 답을 떠받치는 데이터의 토대가 제대로 갖춰져 있는지 먼저 살피는 시야입니다.
세 개의 눈을 한 문장으로 모으면 이렇습니다.
프롬프트는 누구나 쓸 수 있지만, 그 뒤에 무엇이 숨어 있는지 볼 줄 아는 사람만 진짜 인사이트를 얻는다. 그리고 그 '무엇'은 더 똑똑한 AI가 아니라, 우리가 데이터에 부여한 의미다.
AI를 기다리지 마세요. 오늘 '재구매율은 이렇게 센다' 한 줄을 정하는 것이, 다음 버전의 AI보다 당신의 분석을 더 정확하게 만듭니다.
한 걸음 더: Agentic Analytics Stack과 'Sources of Truth'
앞의 네 가지 토대를 Anthropic은 하나의 그림으로 정리했습니다. AI가 스스로 분석하는 시대의 에이전틱 애널리틱스 스택(Agentic Analytics Stack) 입니다 (확인된 출처: Anthropic 공식 블로그).
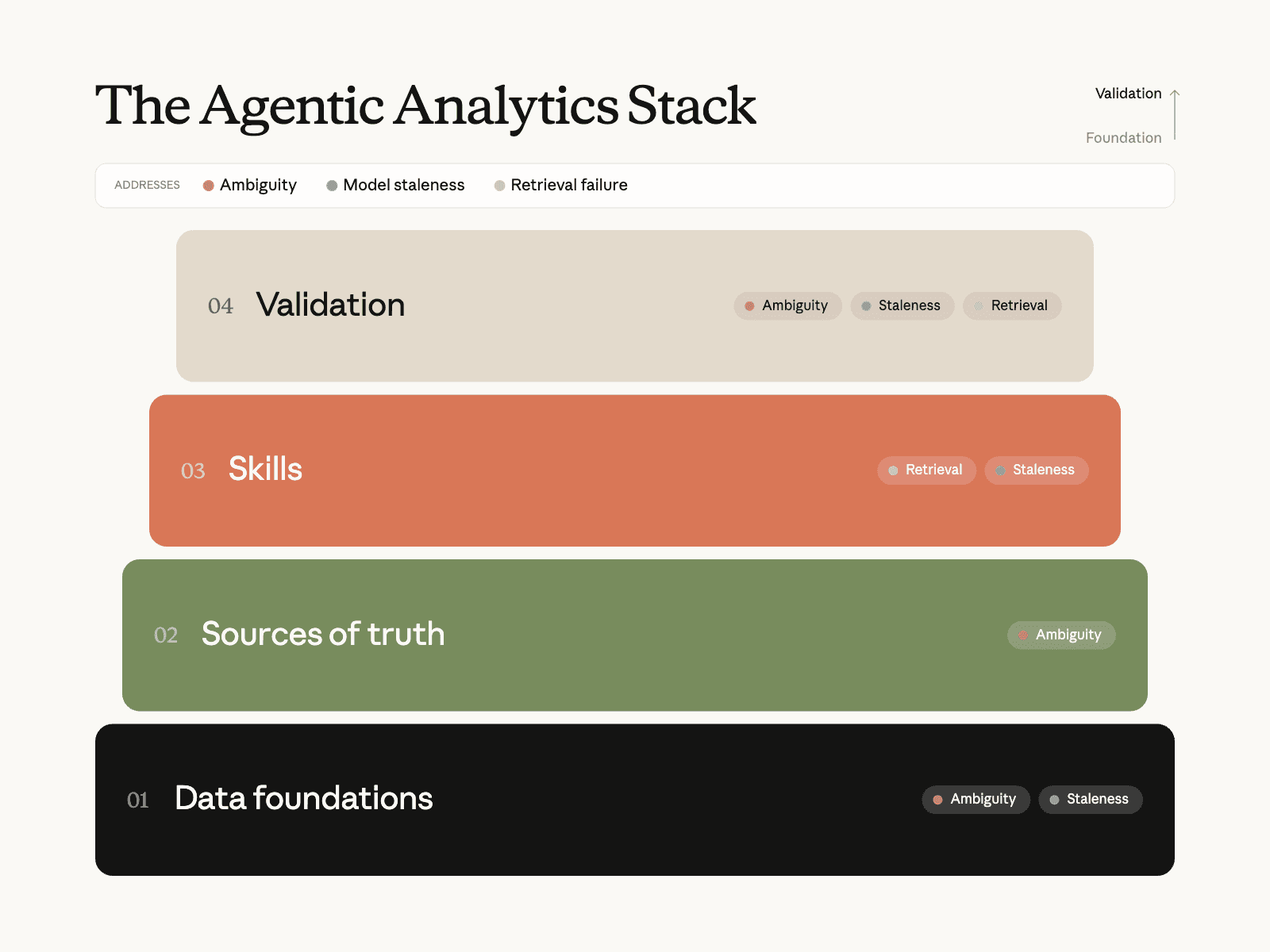
이미지 출처: Anthropic, How Anthropic enables self-service data analytics with Claude
네 개의 층을 쉬운 말로 옮기면 이렇습니다.
1층 - 정규 데이터(Data Foundations): 정답이 하나인 데이터. 모든 분석이 딛고 서는 바닥.
2층 - 진실의 원천(Sources of Truth): 지표 정의(시맨틱 레이어), 데이터의 계보, 비즈니스 맥락 문서. "이것이 우리 회사의 공식 진실"이라고 합의해 둔 묶음.
3층 - 스킬(Skills): "이런 질문엔 어떤 데이터를 어떤 순서로 본다"는 절차를 글로 인코딩해 둔 것. 숙련 분석가의 일하는 방식.
4층 - 검증(Validation): AI 답을 정답지와 대조하고, 한 번 더 비판적으로 되짚는 절차.
'Sources of Truth'가 왜 핵심인가
이 스택에서 가장 중요한 층이 2층, 진실의 원천입니다. 이유는 단순합니다. AI에게 "데이터 창고에서 알아서 찾아 써"라고 맡기면, AI는 가장 그럴듯해 보이는 것을 긁어옵니다(1편의 세 가지 실패 모드가 여기서 터집니다). 반대로 "여기 적힌 정의와 맥락만 진실로 삼아라" 라고 큐레이션된 출처를 정해 주면, AI는 추측 대신 검증된 기준을 따릅니다. 예를 들어 과거 쿼리 기록은 참고는 되지만 그대로 베껴 쓸 '진실'은 아닙니다. 무엇이 진실이고 무엇이 참고인지를 구분해 관리하는 것, 그것이 Sources of Truth의 역할입니다.
스택 전체가 왜 필요한가
사람이 모든 분석을 일일이 검수하던 시절에는 토대가 좀 허술해도 사람이 메웠습니다. 하지만 AI가 자율적으로 분석하는 시대에는 사람이 매번 끼어들 수 없습니다. 그래서 각 층이 가드레일이 되어야 자율 분석을 믿고 맡길 수 있습니다. 실제로 Anthropic 사례에서 AI가 원시 SQL에 직접 손대는 비율은 1% 미만으로 떨어졌습니다. 직관에 맡기지 않고 정해진 토대 위에서만 움직이게 한 결과입니다(확인된 출처: Anthropic 공식 블로그).
이커머스 기업에게 이 스택의 출발점은 거의 항상 2층 - 진실의 원천입니다. 흩어진 고객 데이터를 한곳에 모아 '우리 회사의 공식 정의'를 세우는 일이고, 데이터라이즈가 돕는 지점이 바로 여기입니다.
자주 묻는 질문
Q. 이 토대를 갖추려면 큰 데이터 조직이 필요한가요? A. 아닙니다. 가장 효과가 큰 건 핵심 지표 몇 개의 정의를 문서로 통일하는 것입니다. 작게 시작해 넓혀가는 편이 권장됩니다(확인된 출처: Anthropic 공식 블로그).
Q. 데이터라이즈는 이 중 어디를 돕나요? A. 특히 ①정답이 하나인 데이터와 ②용어 사전의 출발점인 '고객 데이터를 하나의 의미로 모으는' 단계를 돕습니다.
시리즈 끝. 1편 「AI가 준 그 숫자, 믿어도 될까?」, 2편 「'재구매율'이 5개인 회사」도 함께 읽어보세요.
관련 글 더 보기
You may also interested in





Join our newsletter for the latest insights and updates