매일·매주 도는 마케팅 AI 에이전트 28개의 코드를, dynamic workflow로 AI 여러 개를 동시에 풀어 한꺼번에 감사한 경험. 다른 방식과의 차이, 언제 쓰면 좋은지, 그리고 호되게 배운 것 두 가지.

지난 글에서 우리는 마케팅 AI 에이전트 플릿 28개를 어떻게 만들었는지 이야기했습니다. 작은 일꾼들이 각자의 주기로 돌면서 뉴스레터를 쓰고, 블로그를 발행하고, CRM을 동기화하는 그 구조요.
그런데 일꾼이 28개가 되니까 새로운 고민이 생겼습니다. 이 코드를 누가 다 들여다보지?
매일·매주 알아서 도는 에이전트가 28개. 사람 한 명이 한 모듈씩 정독하면 며칠이 걸립니다. 그렇다고 안 보면, 어느 날 조용히 망가진 에이전트를 며칠 뒤에야 발견하게 되죠. 그래서 이번엔 좀 다른 걸 해봤습니다. AI 에이전트 여러 개를 동시에 풀어서, 우리 코드를 한꺼번에 감사하게 만든 겁니다.
이걸 가능하게 한 게 dynamic workflow입니다. 이 글은 그게 뭔지, 다른 방식과 뭐가 다른지, 언제 쓰면 좋은지, 그리고 실제로 우리 플릿에 써보니 어땠는지에 대한 기록입니다.
dynamic workflow가 대체 뭔가
한 줄로 말하면 이렇습니다.
흐름은 코드가 정하고, 일은 AI 여러 개가 나눠서 한다.
말로는 와닿지 않으니, 우리가 거쳐온 네 가지 방식을 늘어놓고 비교하는 게 빠릅니다.
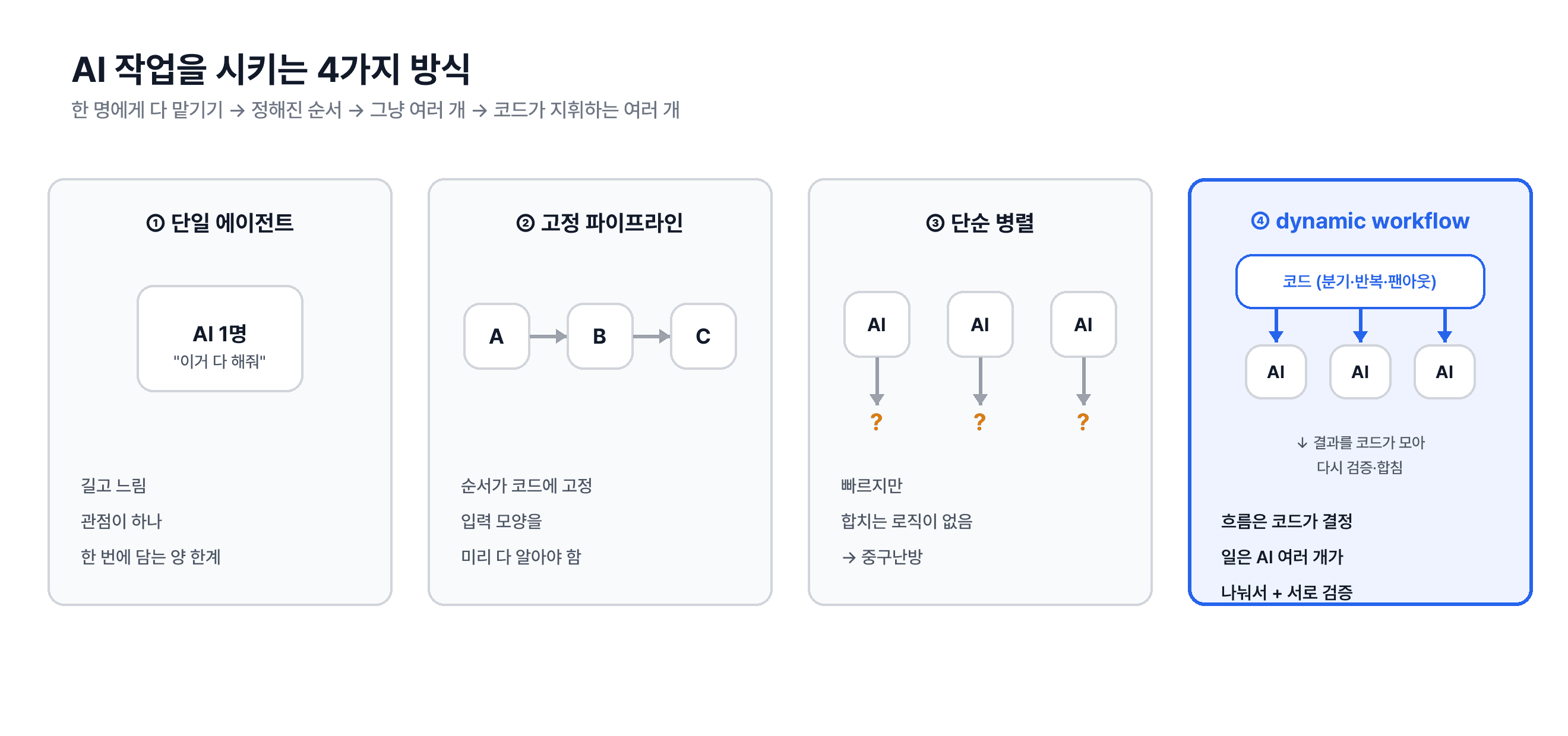
네 가지 접근의 차이. 오른쪽으로 갈수록 "한 명에게 다 맡기기"에서 "코드가 지휘하는 여러 개"로 옮겨간다.
단일 에이전트: AI 한 명한테 "이 코드 28개 다 봐줘"라고 하는 것. 금방 한계가 옵니다. 한 번에 담을 수 있는 양이 정해져 있고, 길어질수록 느리고, 무엇보다 관점이 하나입니다.
고정 파이프라인: "수집 → 분석 → 작성 → 발행"처럼 순서를 코드로 박아둔 것. 우리 뉴스레터 파이프라인이 이렇습니다. 안정적이지만, 흐름이 미리 정해져 있어야 합니다. 작업 도중 "어, 이건 5개로 나눠야겠는데?" 같은 판단을 못 합니다.
단순 병렬: 여러 AI를 한꺼번에 부르긴 하는데, 결과를 어떻게 합칠지가 없는 상태. 빠르지만 중구난방이 됩니다.
dynamic workflow: 여기가 핵심입니다. "몇 개를 어떻게 돌릴지"를 작업 도중 발견한 것에 따라 코드가 결정합니다. 모듈이 28개면 28갈래로 펼치고, 각 갈래는 AI가 맡고, 나온 결과를 코드가 다시 모아 의심하고 검증한 뒤 합칩니다.
눈치채셨을지 모르겠지만, 이건 사실 우리가 플릿을 운영하며 체득한 그 원칙과 똑같습니다. 지난 글의 오케스트레이터(지휘)–워커(실행)–사람(검토) 구조요. dynamic workflow는 그 철학을, 항상 돌아가는 플릿이 아니라 일회성 작업에 적용한 버전입니다. "AI에게 전부 맡기는 것"과 "코드가 지휘하고 AI가 일하는 것"은 생각보다 많이 다릅니다.
그래서 언제 쓰면 되나
만능은 아닙니다. 오히려 대부분의 일상 작업엔 과합니다. 데이터라이즈 마케팅에 적용한 기준은 이렇습니다.
이럴 때 씁니다.
넓게 훑어야 할 때 — 모듈 28개 감사, 경쟁사 리서치, 대규모 코드 마이그레이션처럼 "수가 많고 비슷한 일"
확신이 필요할 때 — 한 AI의 답을 믿기 불안할 때. 독립적인 여러 관점으로 찾고, 찾은 걸 다시 의심하게 만들 때
한 명의 머리에 안 담길 때 — 전체를 한 번에 들고 있기엔 너무 큰 작업
이럴 땐 안 씁니다.
대화하거나 질문에 답할 때
파일 한 줄 고치는 사소한 수정
순서가 뻔하고 분기가 없는 일 (그냥 고정 파이프라인이 낫습니다)
기준을 한 문장으로 줄이면, "여러 갈래로 펼쳐서 동시에 훑고, 나온 걸 서로 검증해야 의미가 있는 일"이면 dynamic workflow입니다.
실전: 우리 플릿을 우리가 감사(audit)했다
자, 이제 진짜 이야기입니다. 우리는 dynamic workflow로 에이전트 코드를 한꺼번에 점검했습니다. 구조는 단순합니다.
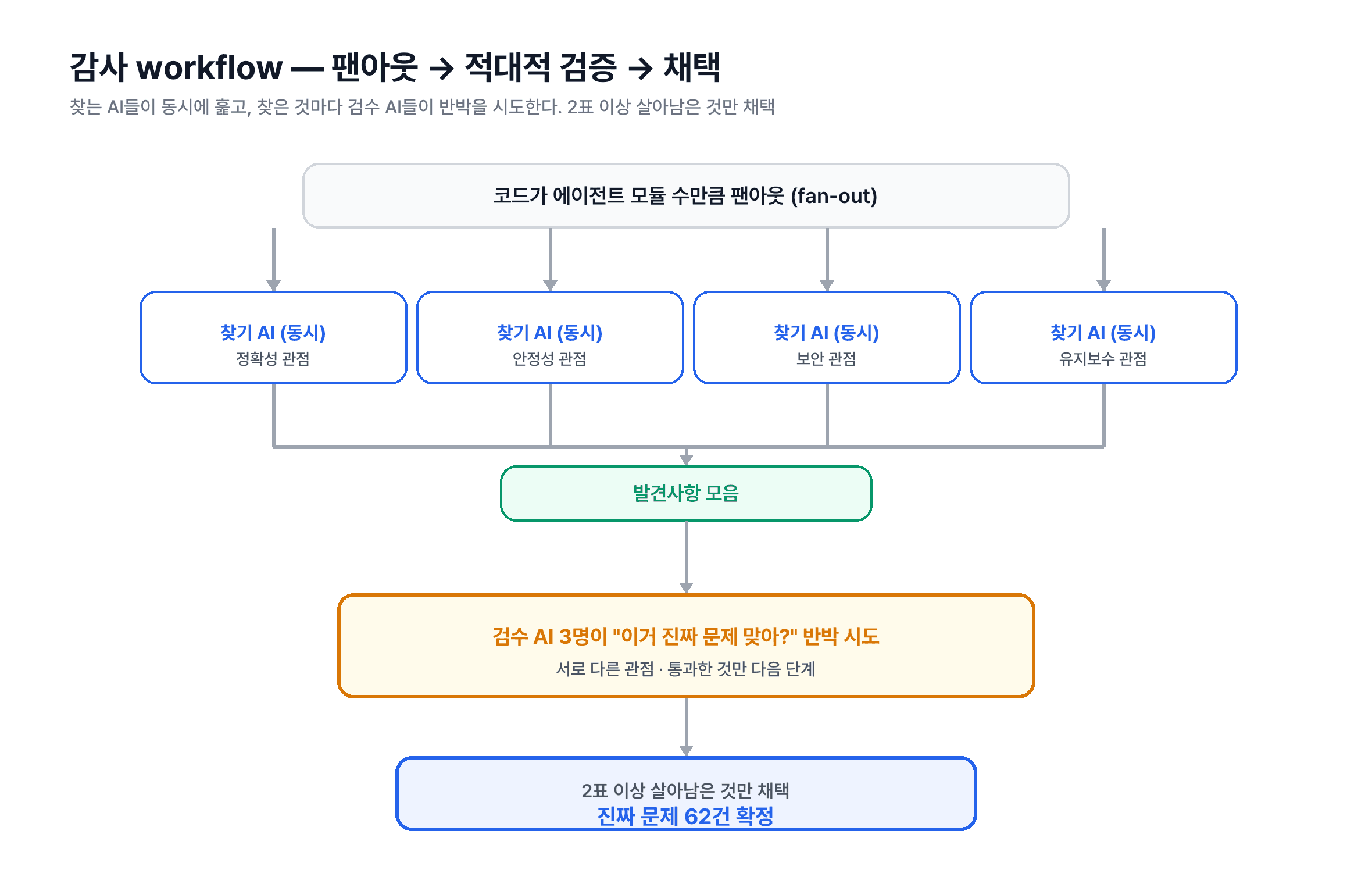
찾는 AI들이 네 관점으로 동시에 펼쳐 훑고, 찾은 것마다 검수 AI들이 "이거 진짜야?"라고 반박한다. 2표 이상 살아남은 것만 채택했다.
찾는 AI들이 모듈마다 동시에 붙어, 네 가지 관점(정확성·안정성·보안·유지보수)으로 훑습니다. 그리고 찾은 지적을 그대로 믿지 않습니다. 검수 AI들이 "그거 진짜 문제 맞아?"라고 반박하게 시킵니다. 2표 이상 살아남은 것만 채택했습니다.
숫자로 보면 이렇습니다.
1차 스캔 | 2차 재검증 | |
|---|---|---|
투입한 AI | 387개 | 45개 |
걸린 시간 | 74분 | 2분 |
결과 | 후보 다수 | 확정 결함 62건 |
사람 한 명이 28개 모듈을 정독하면 며칠 걸렸을 일을, 첫 스캔 74분에 끝냈습니다. "넓게 빠르게 훑기"에 확실히 강했습니다.
비싸게 배운 것 두 가지
여기까지만 쓰면 광고입니다. 솔직히 말하면, 호되게 배운 것도 있습니다.
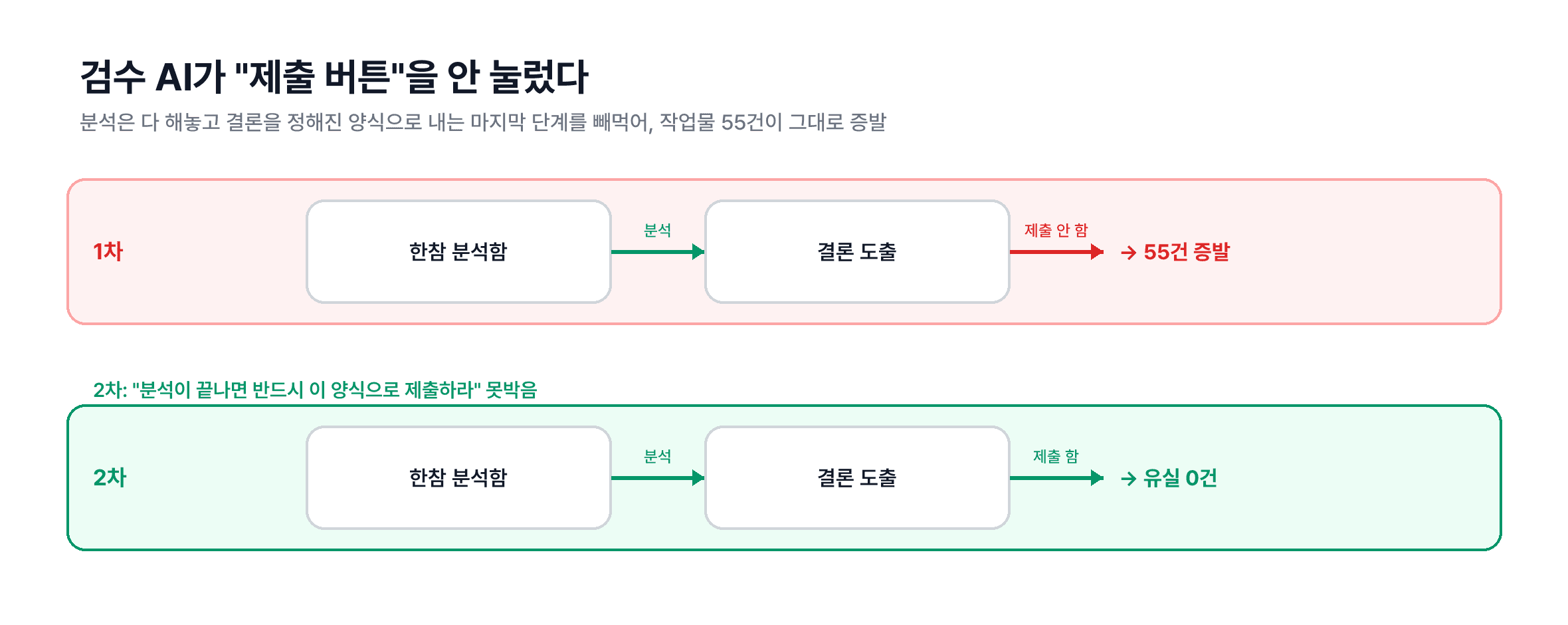
1차에는 검수 AI가 분석을 다 해놓고 "제출 버튼"을 안 눌러 55건이 증발했다. 2차에 양식 제출을 강제하니 유실이 0건이 됐다.
첫째, AI한테도 "보고 양식"을 강제해야 합니다. 1차 때 검수 AI들이 분석은 열심히 해놓고, 마지막에 결론을 정해진 양식으로 제출하는 걸 빼먹어서 작업물 55건이 그대로 증발했습니다. 보고서를 다 써놓고 제출 버튼을 안 누른 셈이죠. 2차 때 "분석이 끝나면 반드시 이 양식으로 결론을 내라"고 못박으니 유실이 0건이 됐습니다. AI를 여러 개 굴릴수록, 똑똑하게 시키는 것만큼 결과를 어떻게 넘길지 규약을 강제하는 게 중요했습니다.
둘째, AI 지적이 그럴듯해도 틀릴 수 있습니다. 한번은 AI가 "이 기능이 연락처를 1만 명까지밖에 못 불러와서 일부가 누락된다"고 자신 있게 지적했습니다. 그런데 알고 보니 그 1만 명 제한은 우리가 쓰지도 않는 다른 조회 방식에만 있는 거였어요. 들은 풍월로 그럴듯하게 단정한 겁니다. 이걸 그대로 믿고 고쳤다면, 멀쩡한 기능을 건드려 없던 문제를 만들 뻔했죠.
그래서 우리의 결론은 플릿 운영 때와 똑같습니다. AI가 찾아준 건 어디까지나 초안이고, 채택 전에 사람이 한 번 더 확인한다. 적대적 검증을 거쳐도, 마지막 판단은 사람이 합니다.
찾은 걸로 뭘 했나
감사로 확정한 62건은 성격별로 묶어 차례로 고쳤습니다. 결이 비슷한 것끼리 정리하면 이렇습니다.
조용한 실패 막기 — 자동화가 실패해도 담당 채널에 알림이 안 가 며칠씩 방치되던 위험을, "실패하면 무조건 알림"으로 통일
원인 추적 가능하게 — 에러가 나도 "왜"가 기록에 안 남던 자리에, 외부 서비스가 돌려준 거절 사유를 그대로 남기도록
외부 값 안전하게 — 외부에서 들어온 입력이 검사 없이 메일·메시지에 박히던 자리를 차단
한계에 안 부딪히게 — 무한 반복으로 멈추거나, 리포트가 너무 커서 발송 자체가 실패하던 경우에 안전장치
성격별로 묶으니 수정 몇 건으로 깔끔하게 반영됐고, 같은 종류의 문제는 공통 장치 하나로 한꺼번에 막을 수 있었습니다. 흩어진 증상이 아니라 패턴으로 보이게 된 것 — 이것도 한꺼번에 훑은 덕이었습니다.
그래서, 추천하나
작고 반복적이고 넓게 훑어야 하는 일이라면, 네. 우리한텐 잘 맞았습니다.
다만 거창하게 시작하지 마세요. 우리가 플릿을 "뉴스레터 한 통"에서 시작했듯, dynamic workflow도 "이 작업, 사람이 하면 며칠 걸리는데 갈래가 뻔히 보인다" 싶은 일 하나부터 써보는 걸 권합니다. 그리고 잊지 마세요. AI 여러 명을 푸는 일일수록, 결과를 받는 규약을 단단히 하고, 마지막엔 사람이 본다.
작게, 책임이 분명하게, 사람이 검토할 수 있게. 플릿을 만들 때 배운 원칙은, 그 플릿을 점검할 때도 똑같이 통했습니다.
あわせて読みたいコンテンツ




最新のECトレンドやお役立ち情報をお届けします。